
Sitemap
A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Pages
Alireza Rafiei's Homepage
Archive Layout with Content
Posts by Category
Posts by Collection
CV
Contact
Page not in menu
Page Archive
Portfolio
Projects and Publications
Sitemap
Posts by Tags
Talk map
Talks and presentations
Teaching
Terms and Privacy Policy
Blog posts
Jupyter notebook markdown generator
Posts
Future Blog Post
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Blog Post number 4
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 3
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 2
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 1
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
honors
publications
SSP: Early prediction of sepsis using fully connected LSTM-CNN model
Sepsis is a life-threatening condition that occurs due to the body’s reaction to infections, and it is a leading cause of morbidity and mortality in hospitals. Early prediction of sepsis onset facilitates early interventions that promote the survival of suspected patients. However, reliable and intelligent systems for predicting sepsis are scarce. This effort presents a novel technique called Smart Sepsis Predictor (SSP) to predict sepsis onset in patients admitted to an intensive care unit (ICU). SSP is a deep neural network architecture that encompasses long short-term memory (LSTM), convolutional, and fully connected layers to achieve early prediction of sepsis. SSP can work in two modes; Mode 1 uses demographic data and vital signs, and Mode 2 uses laboratory test results in addition to demographic data and vital signs. To evaluate SSP, we have used the 2019 PhysioNet/CinC Challenge dataset, which includes the records of 40,366 patients admitted to the ICU. To compare SSP with existing state-of-the-art methods, we have measured the accuracy of the SSP in 4-, 8-, and 12-h prediction windows using publicly available data. Our results show that the SSP performance in Mode 1 and Mode 2 is much higher than existing methods, achieving an area under the receiver operating characteristic curve (AUROC) of 0.89 and 0.92, 0.88 and 0.87, and 0.86 and 0.84 for 4 h, 8 h, and 12 h before sepsis onset, respectively. Using ICU data, sepsis onset can be predicted up to 12 h in advance. Our findings offer an early solution for mitigating the risk of sepsis onset.
[Paper] [UT Distinguished Dissertation Award]
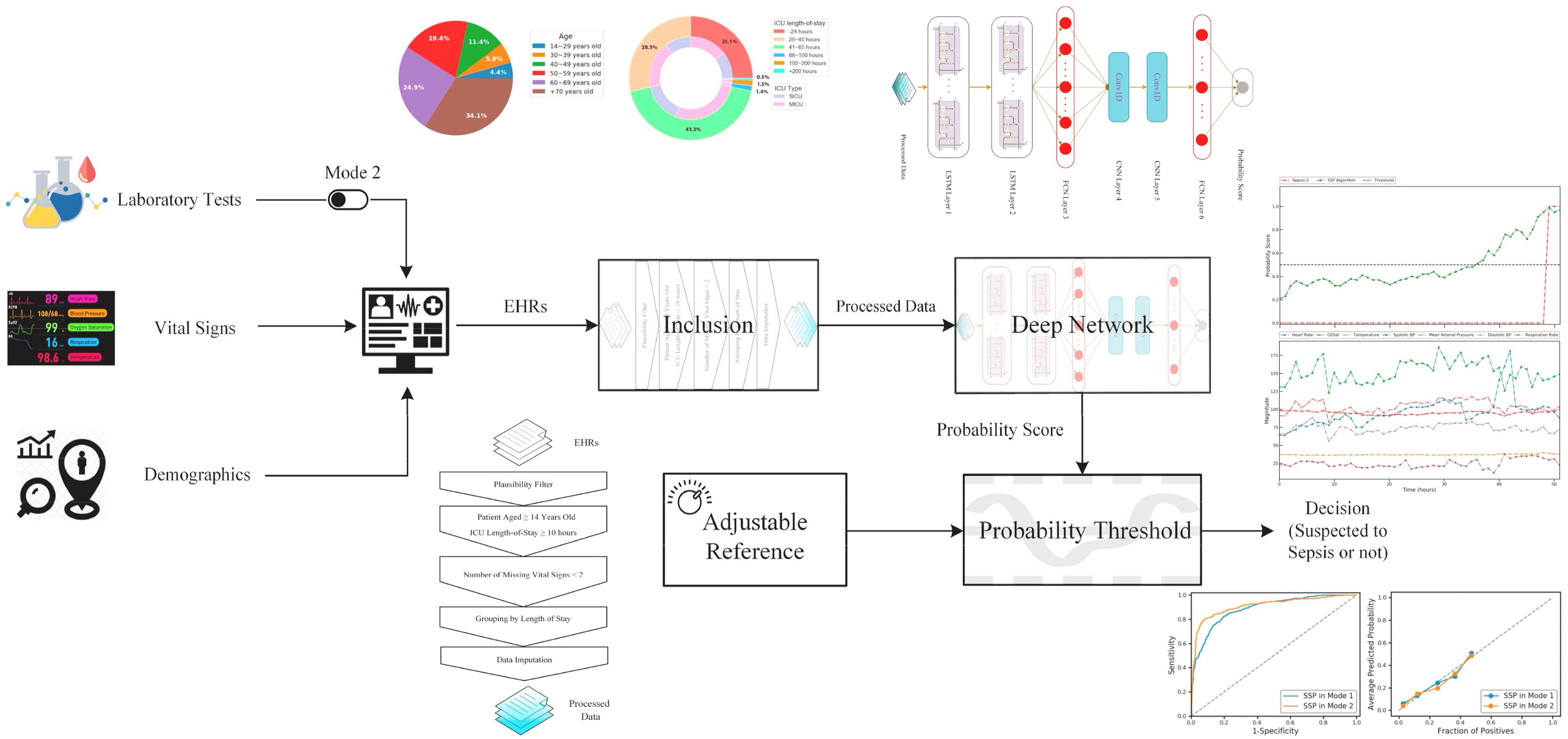
FCOD: Fast COVID-19 Detector based on deep learning techniques
The sudden COVID-19 pandemic has caused serious global concern due to infection and mortality rates. It is a hazardous disease that has become one of the biggest crises of the modern era. Due to the limited availability of test kits and the need for rapid screening and diagnosis, it is essential to develop a self-operating detection model to identify COVID-19 infections and prevent their spread among people. In this paper, we propose a novel technique called Fast COVID-19 Detector (FCOD) for the rapid detection of COVID-19 using X-ray images. FCOD is a deep learning model based on the Inception architecture that uses 17 depthwise separable convolution layers to detect COVID-19. Depthwise separable convolution layers reduce computational costs and processing time while decreasing the number of parameters compared to standard convolution layers. To evaluate FCOD, we used the COVID-ChestXRay dataset, which contains 940 publicly available chest X-ray images. Our results show that FCOD can achieve an accuracy, F1-score, and AUC of 96%, 96%, and 95%, respectively, in classifying COVID-19 in 0.014 seconds per case. The proposed model can be employed as a supportive decision-making system to assist radiologists in clinics and hospitals in screening patients immediately.
[Paper]
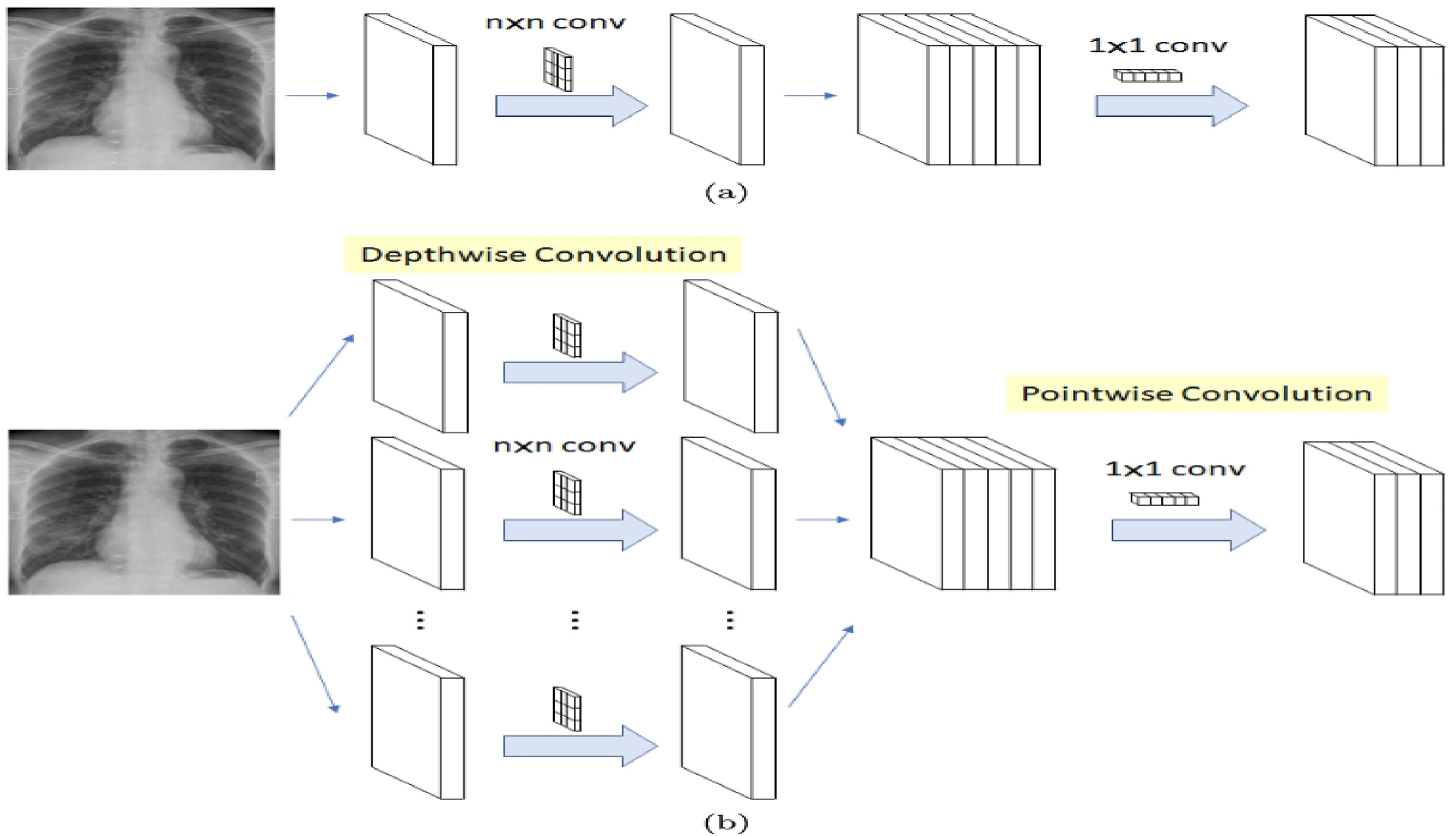
Pedestrian collision avoidance using deep reinforcement learning
One of the main challenges in transportation is the high fatality rate caused by vehicle-pedestrian collisions. This issue is exacerbated by a variety of abnormal and unpredictable situations. This study proposes a novel smart algorithm for pedestrian collision avoidance based on deep reinforcement learning. A deep Q-network (DQN) is designed to learn an optimal driving policy for pedestrian collision avoidance across diverse environments and conditions. The algorithm interacts with both vehicle and pedestrian agents and employs a new reward function to train the model. We used Car Learning to Act (CARLA), an open-source autonomous driving simulator, to train and validate the model under various conditions. Applying the proposed algorithm in a simulated environment reduced vehicle-pedestrian collisions by approximately 64%, depending on the specific conditions. Our findings offer an early-warning solution to reduce the risk of vehicle-pedestrian collisions in real-world scenarios.
[Paper]
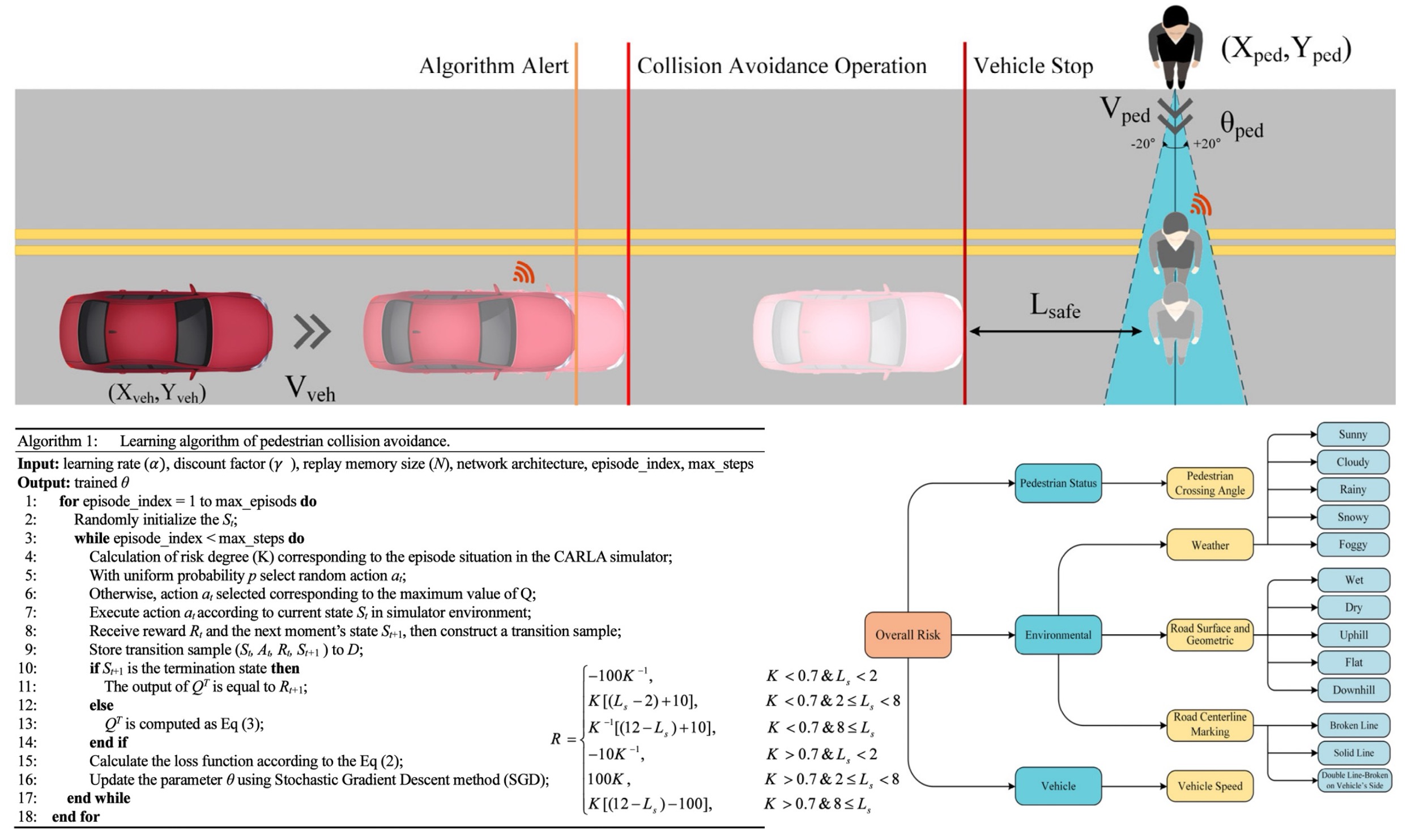
Automated detection of major depressive disorder with EEG signals: a time series classification using deep learning
Major depressive disorder (MDD) is considered a severe and common ailment affecting functional frailty, while its manifestations remain elusive. Hence, the manual detection of MDD is a challenging and subjective task. Although electroencephalogram (EEG) signals have shown promise in aiding diagnosis, further enhancement is required to improve accuracy, clinical utility, and efficiency. This study focuses on the automated detection of MDD using EEG data and deep neural network architecture. For this aim, first, a customized InceptionTime model is developed to detect MDD individuals via 19-channel raw EEG signals. A channel-selection strategy, consisting of three steps, is then applied to eliminate redundant channels. The proposed method achieved 91.67% accuracy using the full set of channels and 87.5% after channel reduction. Our analysis shows that i) only the first minute of EEG recording is sufficient for MDD detection, ii) models based on EEG recorded in eyes-closed resting-state outperform eyes-open conditions, and iii) customizing the InceptionTime model can improve its efficiency for different assignments. The proposed method is able to help clinicians as an efficient, straightforward, and intelligent diagnostic tool for the objective detection of MDD.
[Paper] [GitHub]
EISI: Extended inter-spike interval for mental health patients clustering based on mental health services and medications utilisation
Mental health is vital in all human life stages, and managing mental healthcare service resources is crucial for providers. This study presents a new unsupervised learning algorithm, called Extended Inter-Spike Interval (EISI), on identifying the patients with a similar utilisation of mental health services and medications. The EISI measures the distance between the utilisation patterns of the patients. Then, the pairwise distances are given to a developed split-and-merge Partitioning Around Medoids (PAM) clustering method to identify the patients with similar utilisation patterns. To evaluate the proposed method, we use two years (2013–2014) of the 10% publicly available sample of the Australian Medicare Benefits Schedule (MBS) and Pharmaceutical Benefits Scheme (PBS) administrative data. Results show that mental health patients can be grouped into ten clusters with distinct and interpretable utilisations patterns. The largest cluster comprises individuals who only visit general practitioners and take psycholeptics medications for a short time. The smallest group contains occasional visits with general practitioners and regularly utilises psycholeptics and psychoanaleptics medications over long periods. The proposed method provides insights on whom to target and how to structure services for different groups of individuals with mental health conditions.
[Paper]
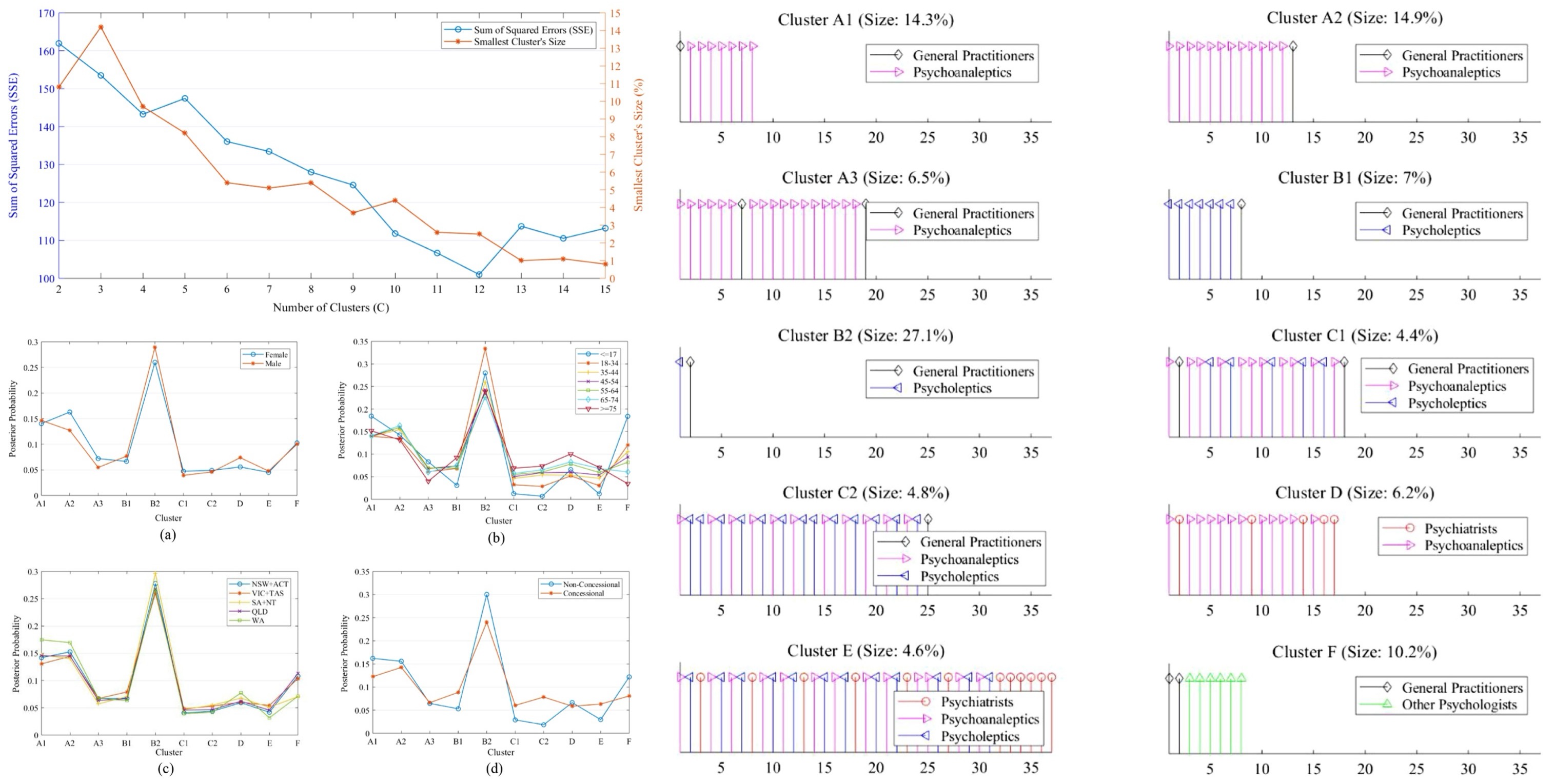
Automated major depressive disorder classification using deep convolutional neural networks and Choquet fuzzy integral fusion
Major depressive disorder (MDD) is a common and severe ailment impacting functional frailty, while its concrete manifestations have been shrouded in mystery. Hence, manual diagnosis of MDD is an arduous and subjective task. Despite the aid of electroencephalogram (EEG) signals in the detection, developing intelligent systems are required to improve clinical utility, performance, and efficiency. In this study, we focus on the automated detection of MDD via raw EEG data using convolutional neural networks (CNN). For this objective, we first extracted the short-time Fourier transform (STFT) of EEG records for five distinct band powers and created an image representing the frequency oscillation of every channel during a resting state. Afterward, we applied three approaches to determine whether a subject is MDD or a Healthy individual. In the first approach, a 2D-CNN model was developed for each band power to detect MDD separately. Second, the outcomes of the developed models were used to establish a Choquet fuzzy integral fusion to classify subjects using all of the previous models. The third approach was dedicated to introducing a 3D-CNN architecture. This model received three-dimensional data by putting different band powers’ images together. The two last approaches achieved a 95.65% accuracy and 100% sensitivity to detect MDD. The proposed approaches can help clinicians as straightforward, efficient, and intelligent diagnostic tools for detecting MDD.
[Paper] [GitHub]
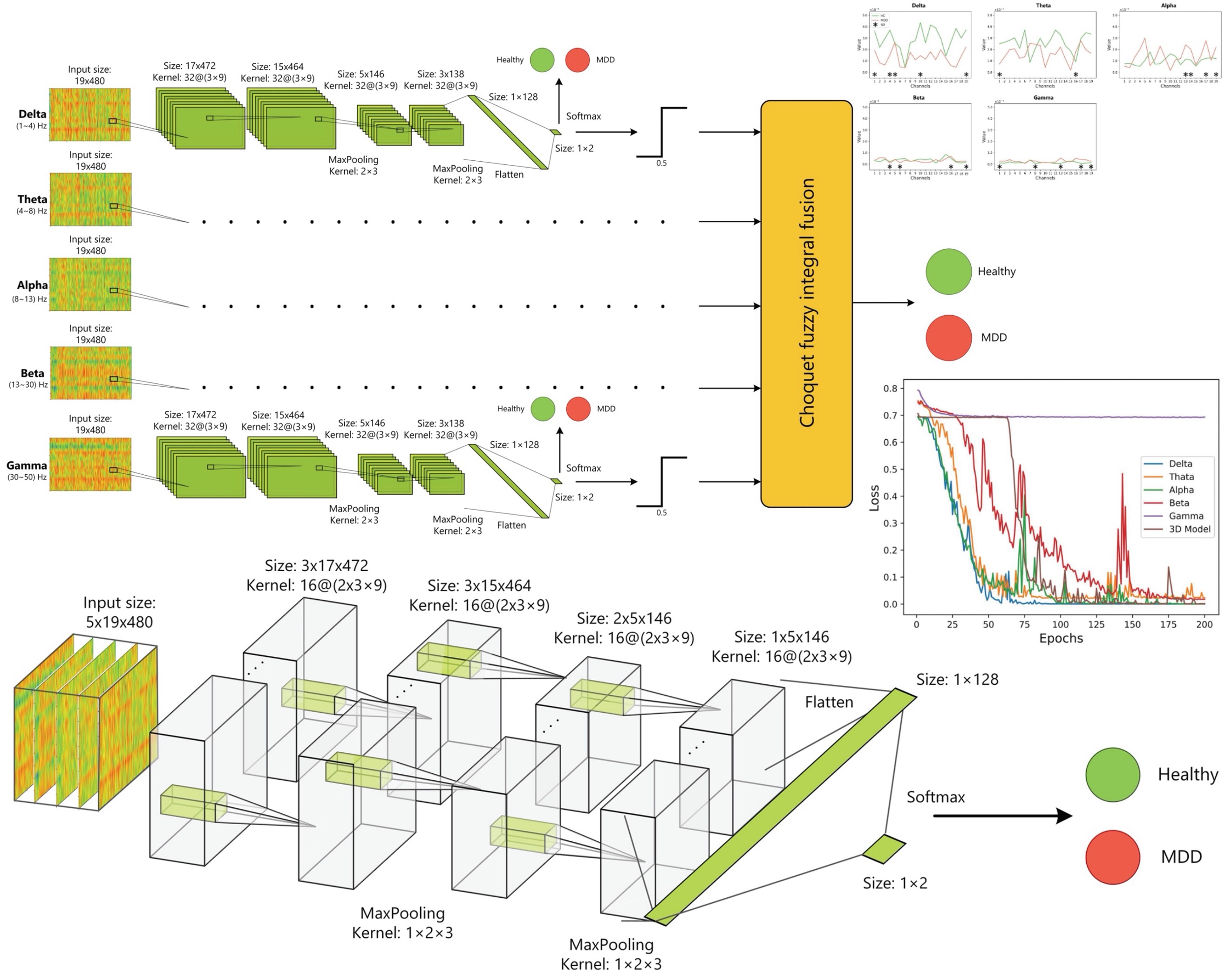
Pharmacophenotype identification of intensive care unit medications using unsupervised cluster analysis of the ICURx common data model
Identifying patterns within ICU medication regimens may help artificial intelligence algorithms to better predict patient outcomes; however, machine learning methods incorporating medications require further development, including standardized terminology. The Common Data Model for Intensive Care Unit (ICU) Medications (CDM-ICURx) may provide important infrastructure to clinicians and researchers to support artificial intelligence analysis of medication-related outcomes and healthcare costs. Using an unsupervised cluster analysis approach in combination with this common data model, the objective of this evaluation was to identify novel patterns of medication clusters (termed ‘pharmacophenotypes’) correlated with ICU adverse events and patient-centered outcomes. This was a retrospective, observational cohort study of 991 critically ill adults. To identify pharmacophenotypes, unsupervised machine learning analysis with automated feature learning using restricted Boltzmann machine and hierarchical clustering was performed on the medication administration records of each patient during the first 24 h of their ICU stay. Distributions of medications across pharmacophenotypes were described, and differences among patient clusters were compared using signed rank tests and Fisher’s exact tests, as appropriate. A total of 30,550 medication orders for the 991 patients were analyzed; five unique patient clusters and six unique pharmacophenotypes were identified. For patient outcomes, compared to patients in Clusters 1 and 3, patients in Cluster 5 had a significantly shorter duration of mechanical ventilation and ICU length of stay; for medications, Cluster 5 had a higher distribution of Pharmacophenotype 1 and a smaller distribution of Pharmacophenotype 2, compared to Clusters 1 and 3. For outcomes, patients in Cluster 2, despite having the highest severity of illness and greatest medication regimen complexity, had the lowest overall mortality; for medications, Cluster 2 also had a comparably higher distribution of Pharmacophenotype 6. The results of this evaluation suggest that patterns among patient clusters and medication regimens may be observed using empiric methods of unsupervised machine learning in combination with a common data model. These results have potential because while phenotyping approaches have been used to classify heterogenous syndromes in critical illness to better define treatment response, the entire medication administration record has not been incorporated in those analyses. Applying knowledge of these patterns at the bedside requires further algorithm development and clinical application but may have the future potential to be leveraged in guiding medication-related decision making to improve treatment outcomes.
[Paper] [GitHub] [ACCP 2023 CC Paper of the Year]
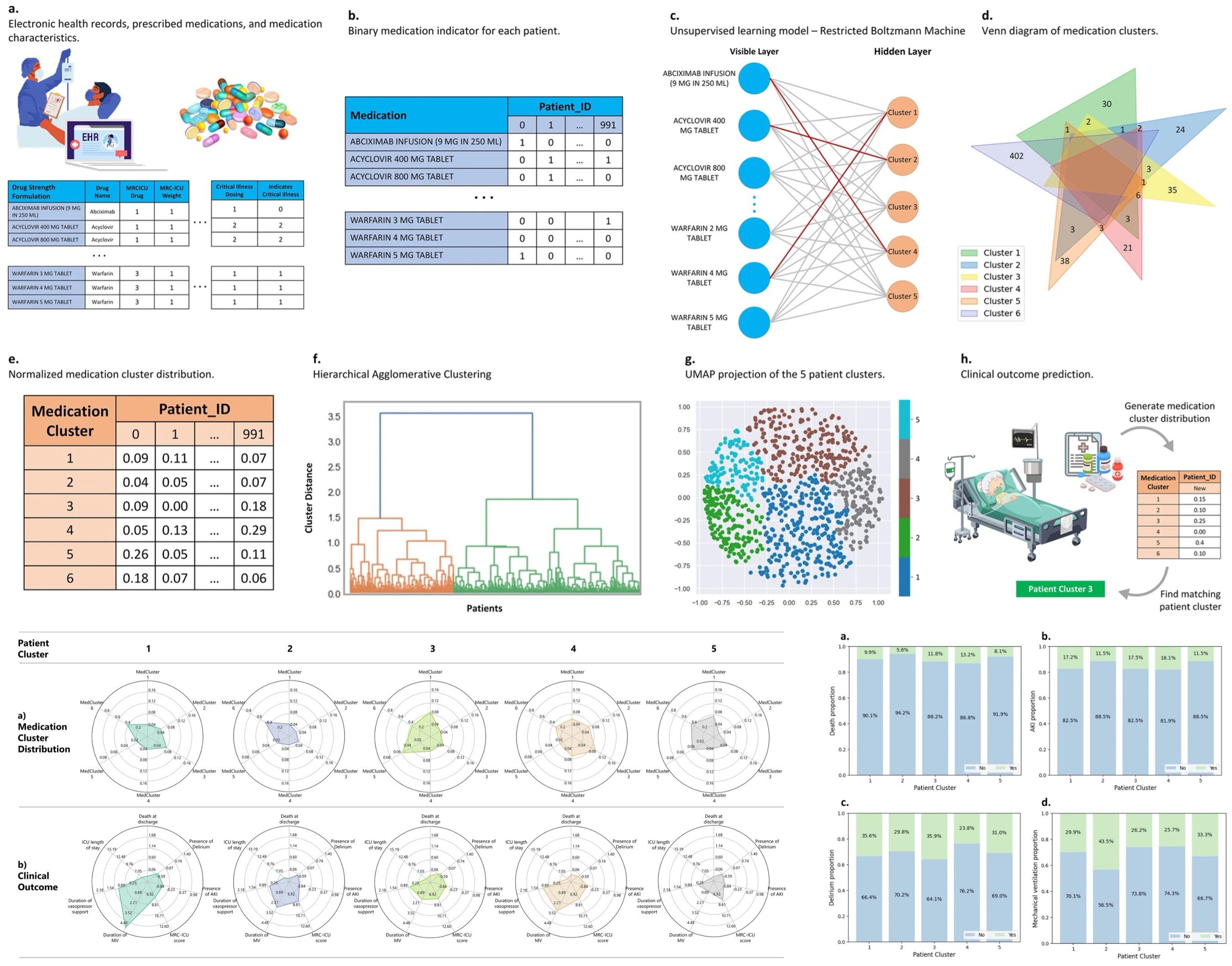
Development and validation of a model for endotracheal intubation and mechanical ventilation prediction in PICU patients
Predicting the need for intubation in pediatric intensive care units (PICUs) is critical for timely intervention and resource allocation. This study aimed to develop and externally validate a machine learning model to predict intubation in children admitted to a PICU using routinely available electronic medical record (EMR) data. A retrospective observational cohort study was conducted across two PICUs within the same healthcare system, including a quaternary academic center and a tertiary community hospital. Clinical data were extracted from the EMR, focusing on PICU stays where mechanical ventilation occurred for at least 24 hours within 1–7 days of hospital admission. In the derivation cohort (n = 13,208), 8.90% of stays included an intubation event, while in the validation cohort (n = 17,841), 6.53% of stays required intubation. A Categorical Boosting (CatBoost) model was trained using vital signs, laboratory results, demographic data, medications, and organ dysfunction scores to predict intubation within a 24-hour observation window. The model outperformed extreme gradient boosting, random forest, and logistic regression models, achieving an area under the receiver operating characteristic curve (AUC) of 0.88 (95% CI, 0.88–0.89) in the derivation cohort and 0.92 (95% CI, 0.91–0.92) in the validation cohort. The study demonstrates that an interpretable machine learning model can effectively predict the need for intubation in PICU patients, offering a valuable tool to enhance clinical decision-making. Implementation of this model may improve the timing of intubation and optimize resource allocation for mechanically ventilated children.
[Paper] [Editor’s Choice]
Improving mixed-integer temporal modeling by generating synthetic data using conditional generative adversarial networks: A case study of fluid overload prediction in the intensive care unit
The challenge of mixed-integer temporal data, which is particularly prominent for medication use in the critically ill, limits the performance of predictive models. The purpose of this evaluation was to pilot test integrating synthetic data within an existing dataset of complex medication data to improve machine learning model prediction of fluid overload. This retrospective cohort study evaluated patients admitted to an ICU ≥ 72 h. Four machine learning algorithms to predict fluid overload after 48–72 h of ICU admission were developed using the original dataset. Then, two distinct synthetic data generation methodologies (synthetic minority over-sampling technique (SMOTE) and conditional tabular generative adversarial network (CTGAN)) were used to create synthetic data. Finally, a stacking ensemble technique designed to train a meta-learner was established. Models underwent training in three scenarios of varying qualities and quantities of datasets. Training machine learning algorithms on the combined synthetic and original dataset overall increased the performance of the predictive models compared to training on the original dataset. The highest performing model was the meta-model trained on the combined dataset with 0.83 AUROC while it managed to significantly enhance the sensitivity across different training scenarios. The integration of synthetically generated data is the first time such methods have been applied to ICU medication data and offers a promising solution to enhance the performance of machine learning models for fluid overload, which may be translated to other ICU outcomes. A meta-learner was able to make a trade-off between different performance metrics and improve the ability to identify the minority class.
[Paper] [GitHub]
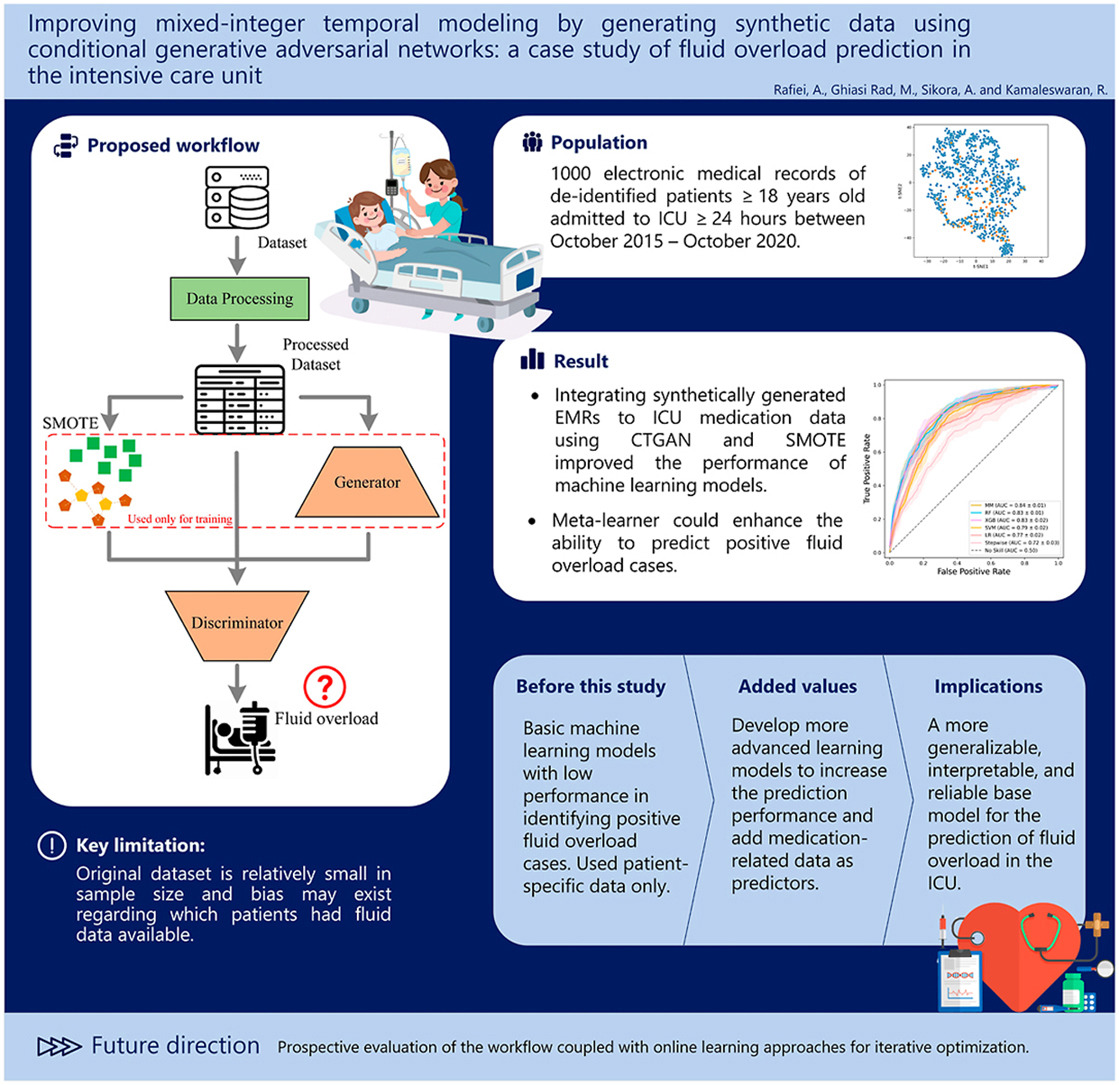
Robust Meta-Model for Predicting the Likelihood of Receiving Blood Transfusion in Non-traumatic Intensive Care Unit Patients
Blood transfusions, crucial in managing anemia and coagulopathy in intensive care unit (ICU) settings, require accurate prediction for effective resource allocation and patient risk assessment. However, existing clinical decision support systems have primarily targeted a particular patient demographic with unique medical conditions and focused on a single type of blood transfusion. This study aims to develop an advanced machine learning-based model to predict the probability of transfusion necessity over the next 24 h for a diverse range of non-traumatic ICU patients. We conducted a retrospective cohort study on 72,072 non-traumatic adult ICU patients admitted to a high-volume US metropolitan academic hospital between 2016 and 2020. We developed a meta-learner and various machine learning models to serve as predictors, training them annually with 4-year data and evaluating on the fifth, unseen year, iteratively over 5 years. The experimental results revealed that the meta-model surpasses the other models in different development scenarios. It achieved notable performance metrics, including an area under the receiver operating characteristic curve of 0.97, an accuracy rate of 0.93, and an F1 score of 0.89 in the best scenario. This study pioneers the use of machine learning models for predicting the likelihood of blood transfusion receipt in a diverse cohort of critically ill patients. The findings of this evaluation confirm that our model not only effectively predicts transfusion reception but also identifies key biomarkers for making transfusion decisions.
[Paper] [News1] [News2] [News3] [News4] [News5] [News6] [News7]
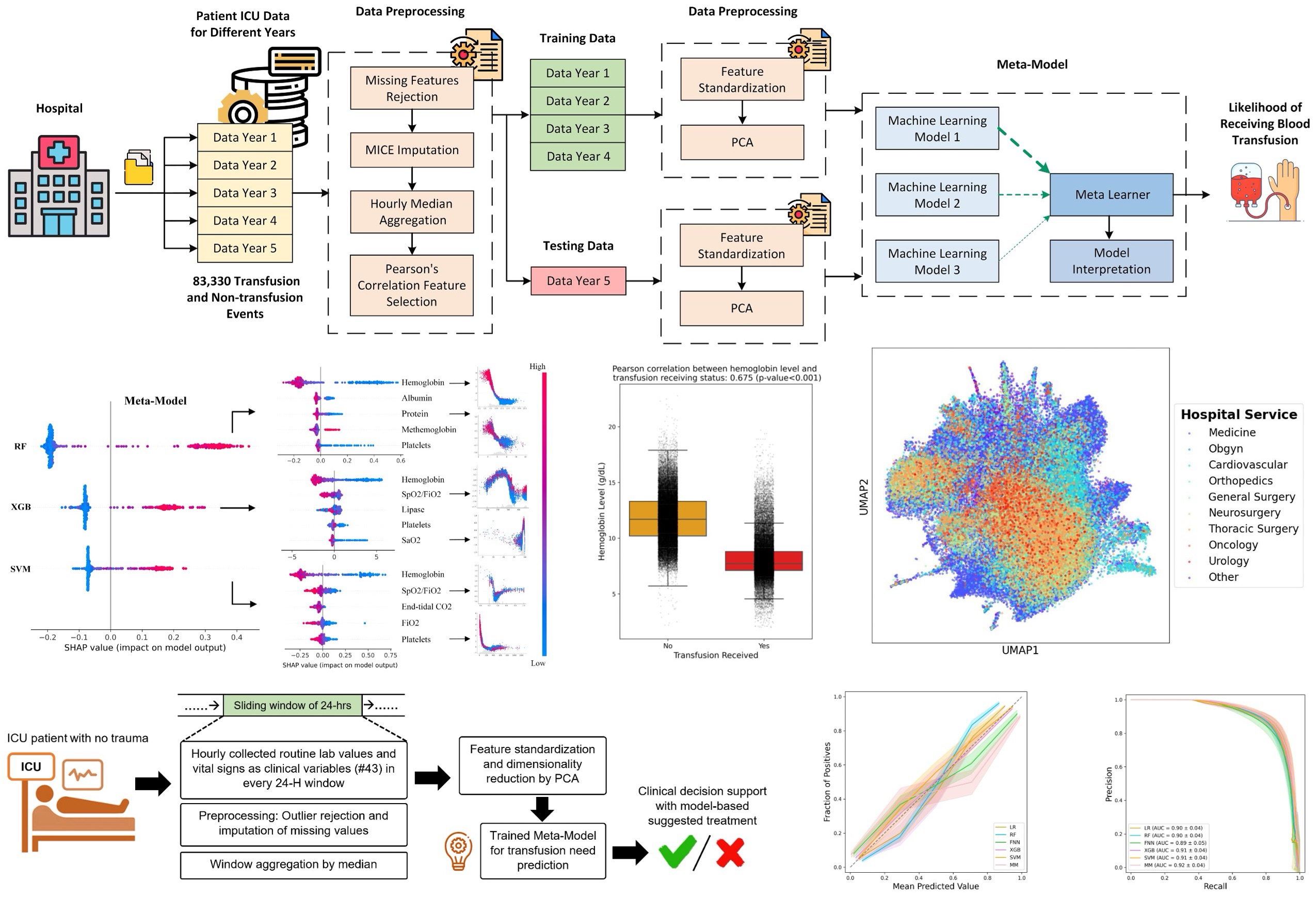
Social Media as a Sensor: Analyzing Twitter Data for Breast Cancer Medication Effects Using Natural Language Processing
Breast cancer is a significant public health concern and is the leading cause of cancer-related deaths among women. Despite advances in breast cancer treatments, medication non-adherence remains a major problem. As electronic health records do not typically capture patient-reported outcomes that may reveal information about medication-related experiences, social media presents an attractive resource for enhancing our understanding of the patients’ treatment experiences. In this research, we developed natural language processing (NLP) based methodologies to study information posted by an automatically curated breast cancer cohort from social media. We employed a transformer-based classifier to identify breast cancer patients/survivors on X (Twitter) based on their self-reported information, and we collected longitudinal data from their profiles. We then designed a multi-layer rule-based model to develop a breast cancer therapy-associated side effect lexicon and detect patterns of medication usage and associated side effects among breast cancer patients. 1,454,637 posts were available from 583,962 unique users, of which 62,042 (10.6%) were detected as breast cancer members using our transformer-based model. 198 cohort members mentioned breast cancer medications, with tamoxifen as the most common. Our side effect lexicon identified well-known side effects of hormone and chemotherapy. Furthermore, it discovered a subjective feeling towards cancer and medications, which may suggest a pre-clinical phase of side effects or emotional distress. This analysis highlighted not only the utility of NLP techniques in unstructured social media data to identify self-reported breast cancer posts, medication usage patterns, and treatment side effects but also the richness of social data to answer such clinical questions.
[Paper] [GitHub]
2024 Pediatric Sepsis Data Challenge
This competition aims to facilitate the development of open-source algorithms to predict in-hospital mortality in children with sepsis. The challenge is to first develop an algorithm using a synthetic training dataset, which will then be scored according to standard diagnostic testing criteria, and then be evaluated against a nonsynthetic test dataset. The datasets originate from admissions to six hospitals in Uganda (2017–2020) and include 3837 children, 6 to 60 months old, who were confirmed or suspected to have a diagnosis of sepsis. The synthetic dataset was created from a random subset of the original data. The test validation dataset closely resembles the synthetic dataset. The challenge should generate an optimal model for predicting in-hospital mortality. Following external validation, this model could be used to improve the outcomes for children with proven or suspected sepsis in low- and middle-income settings.
[Paper] [Editor’s Choice] [GitHub] [Dataset] [Website]

Waveform Clustering using Generative AI
TBA
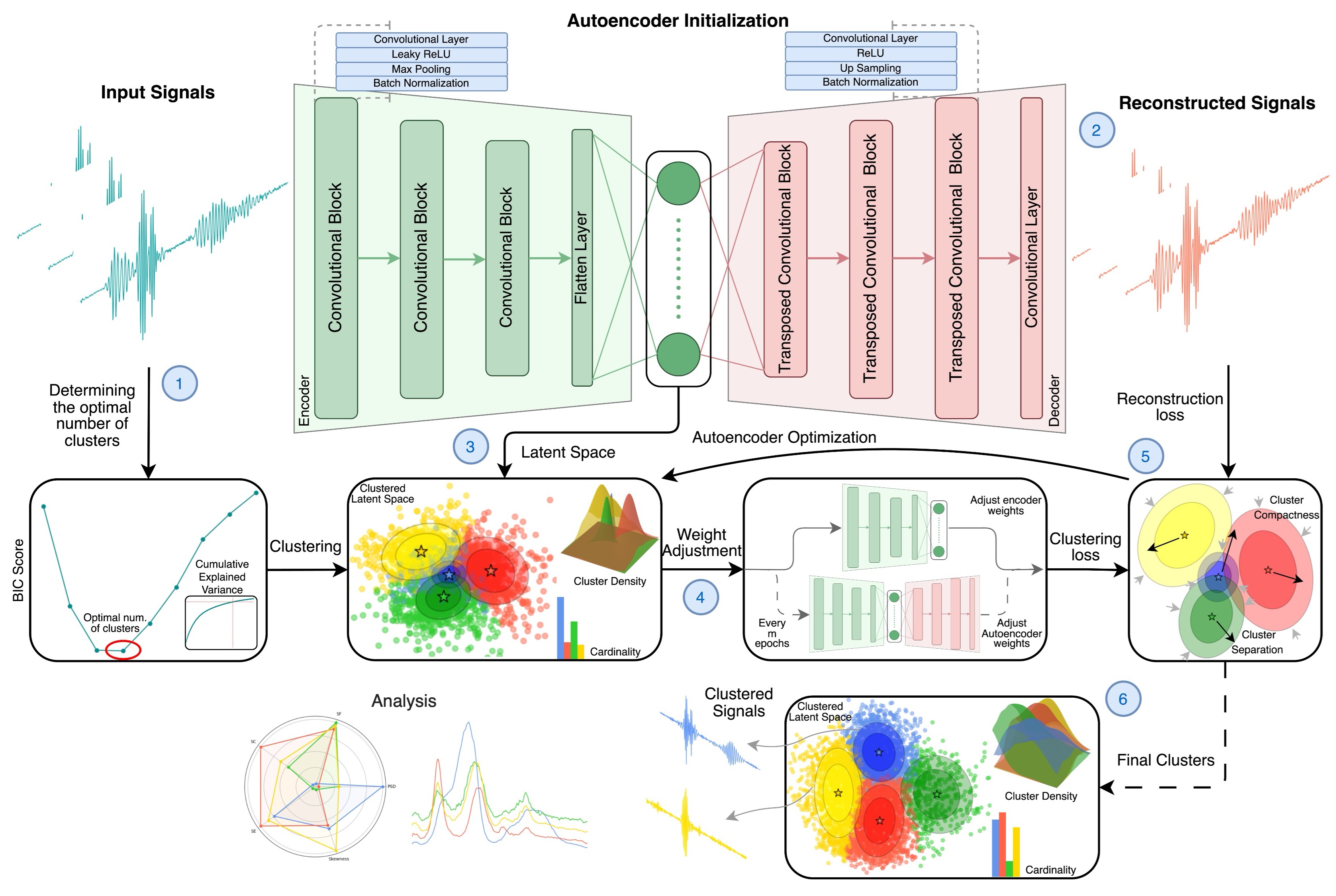
Leveraging Neural Sequential Modeling for Cardiac Activity Analysis
TBA 
Conditional Aware MultiModal Diffusion Model for Signal Synthesis
TBA 
research
SSP: Early prediction of sepsis using fully connected LSTM-CNN model
Sepsis is a life-threatening condition that occurs due to the body’s reaction to infections, and it is a leading cause of morbidity and mortality in hospitals. Early prediction of sepsis onset facilitates early interventions that promote the survival of suspected patients. However, reliable and intelligent systems for predicting sepsis are scarce. This effort presents a novel technique called Smart Sepsis Predictor (SSP) to predict sepsis onset in patients admitted to an intensive care unit (ICU). SSP is a deep neural network architecture that encompasses long short-term memory (LSTM), convolutional, and fully connected layers to achieve early prediction of sepsis. SSP can work in two modes; Mode 1 uses demographic data and vital signs, and Mode 2 uses laboratory test results in addition to demographic data and vital signs. To evaluate SSP, we have used the 2019 PhysioNet/CinC Challenge dataset, which includes the records of 40,366 patients admitted to the ICU. To compare SSP with existing state-of-the-art methods, we have measured the accuracy of the SSP in 4-, 8-, and 12-h prediction windows using publicly available data. Our results show that the SSP performance in Mode 1 and Mode 2 is much higher than existing methods, achieving an area under the receiver operating characteristic curve (AUROC) of 0.89 and 0.92, 0.88 and 0.87, and 0.86 and 0.84 for 4 h, 8 h, and 12 h before sepsis onset, respectively. Using ICU data, sepsis onset can be predicted up to 12 h in advance. Our findings offer an early solution for mitigating the risk of sepsis onset.
[Paper] [UT Distinguished Dissertation Award]
Meta-learning in healthcare: A survey
As a subset of machine learning, meta-learning, or learning to learn, aims at improving the model’s capabilities by employing prior knowledge and experience. A meta-learning paradigm can appropriately tackle the conventional challenges of traditional learning approaches, such as insufficient number of samples, domain shifts, and generalization. These unique characteristics position meta-learning as a suitable choice for developing influential solutions in various healthcare contexts, where the available data is often insufficient, and the data collection methodologies are different. This survey discusses meta-learning broad applications in the healthcare domain to provide insight into how and where it can address critical healthcare challenges. We first describe the theoretical foundations and pivotal methods of meta-learning. We then divide the employed meta-learning approaches in the healthcare domain into two main categories of multi/single-task learning and many/few-shot learning and survey the studies. Finally, we highlight the current challenges in meta-learning research, discuss the potential solutions and provide future perspectives on meta-learning in healthcare.
Paper 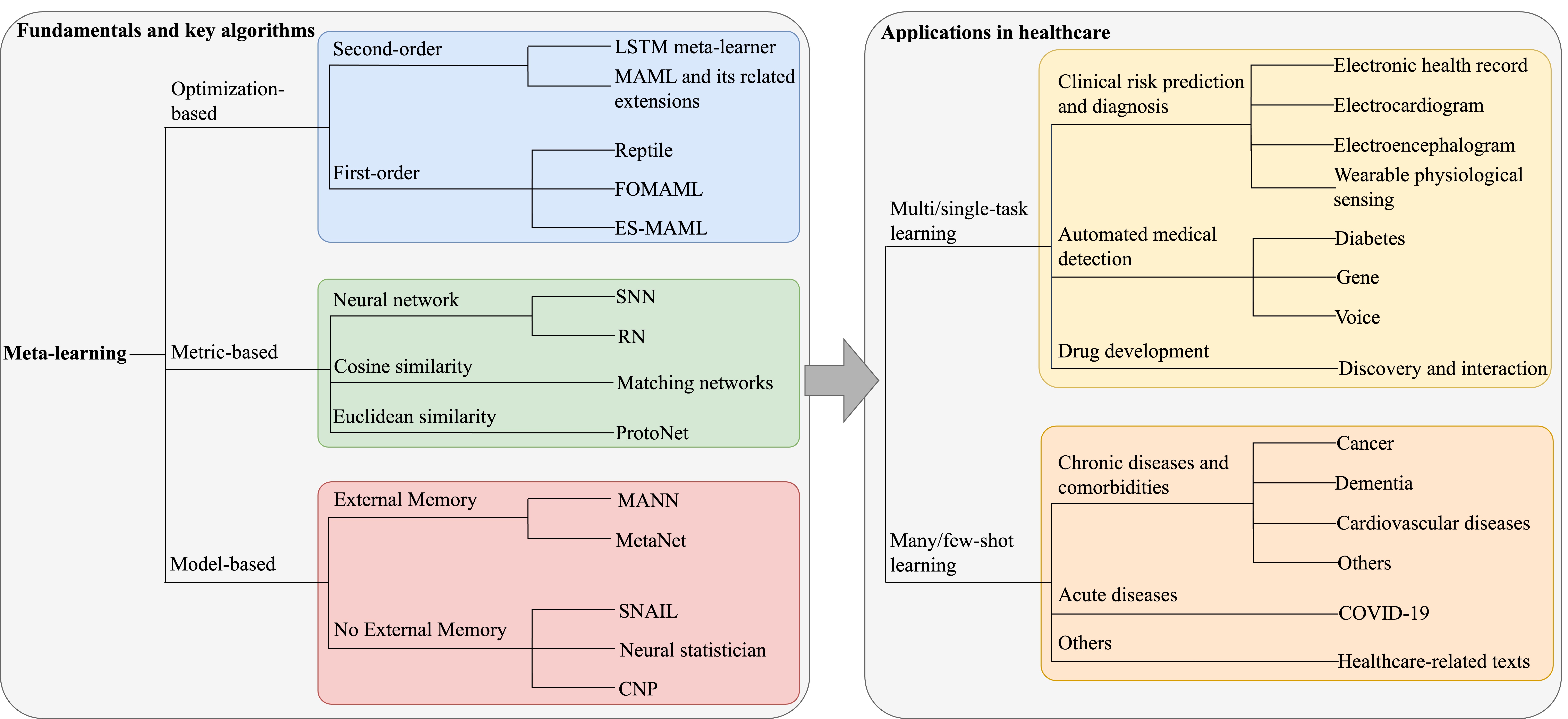
talks
Talk 1 on Relevant Topic in Your Field
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Tutorial 1 on Relevant Topic in Your Field
Talk 2 on Relevant Topic in Your Field
Conference Proceeding talk 3 on Relevant Topic in Your Field
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.